
Introduction
Around two years ago Unity published the first version of their new tech-stack regarding “Performance by default”. The big thing everybody was talking about was their new Entity-Component-System (ECS) that enabled super fast CPU-based simulations like the Boid demo and the Mega-City.
The key aspects to reach this high performance are:
- Cache friendly memory layout
- Parallelization
- Compiler optimization
In this article I will focus on those patterns, show how Unity utilizes them and how this affects the performance.
The new Unity-Tech-Stack consists of several new libraries. They all are created with those principles in mind.
- The Job-System lets you parallelize your work on several CPU’s which was not possible before with Unity.
- The Burst-Compiler generates super fast vectorized code using LLVM.
- The Entity-Component-System helps you store and access your data in a cache efficient way
- The Collections-API gives you direct access to non-managed memory
- The Math library adds new vector types like float3, that you already know from shader languages and enables the Burst-compiler to vectorize your math operations
The Job-System and the Burst-Compiler can be independently used from ECS. The last chapter will show an example how this works
In the next sections I will explain those three key aspects and describe how Unity has implemented them.
1.) Cache friendly memory layout
Data-Oriented-Design
Data-oriented-design is all about organizing your data for efficient processing. The goal is to avoid cache misses as much as possible to feed your CPU’s with data as fast as possible. You as a developer should think about how your data is layed out in memory. When you code in an object-oriented way, you mostly loose control over your memory layout or you know your layout, but it is completely inefficient. Programming in a Data-Oriented style, means that you think first how your data looks and how you need to access it. Based on those aspects you design your data layout before you even start to write one line of your actual code. The following section will explain important key points that you need to know to design your data in an efficient way.
Cache Misses
Modern CPU´s are so fast, that the bandwidth and latency between RAM and the registers of the CPU is often the limiting factor and not the speed of the CPU. That is the reason why several cache levels are created between RAM and registered to reduce latency.
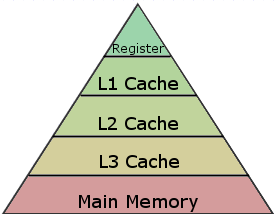
The diagram shows a memory pyramid. The closer you get to the CPU (the registers) the smaller the memory gets. At the same time, the closer you are to the CPU, the faster is the access speed. When the CPU needs a value, it first looks it up in the cache starting at L1. If it´s not in the Cache, it needs to be loaded from main memory, which is very slow. The following table shows the cache sizes of an Intel Core i7-8700K
| Cache | Size |
| L1 Cache (Data) | 192 KB |
| L1 Cache (Instructions) | 192 KB |
| L2 Cache | 1,5 MB |
| L3 Cache | 12 MB |
The next table contains (approximated) access times of an Intel Core i7-4770
| Operation | CPU cycles |
| Execute typical instruction | 1 |
| L1 | 4 |
| L2 | 12 |
| L3 | 36 |
| Fetch from main memory | 36 + ~100 ns |
As you can see the further the data is away from the CPU the longer it takes to load the data into a register. To avoid those long loading times, it´s absolutely necessary to avoid cache misses as much as possible. Therefore you need to understand how the cache is accessed.
Cache Lines
Today’s CPUs do not access memory byte by byte. Instead, they fetch memory in chunks of (typically) 64 bytes, called cache lines. When you read a particular memory location, the entire cache line is fetched from the main memory into the cache. Accessing other values from the same cache line is cheap! This follows the “Principle of locality” that data which is used close in time is usually also stored close in memory. If you for example iterate over an array of integers, 8 Integer values are loaded at the same time (64 bytes cache line size / 4 byte per Integer = 8). This prevents cache misses on every value read. Furthermore a cache is also smart enough to prefetch the previous or next cache line required, depending upon the instruction. So, the more predictable is your access pattern is, the better the performance will be.
Data Layout
Class vs Structs
In C# you have the choice to define your data as class or as struct. The difference for performance is huge, because structs are value types, which are stored totally different in memory.

The diagram shows two arrays. The top one is an array of structs or primitive types (e.g. int[]). Because the size of the struct is known at compile time, the elements can be tightly packed into memory, one element after another. This is not true for an array of a class type. Because of polymorphy, every element can have a different size, making it impossible to pack them one after another. Instead the array stores pointers (nowadays 64 bit) to other locations on the heap where the actual data is stored. The elements are randomly distributed depending on when they were created with the “new” operator – not when the array was created.
The following code is a small test to show the performance difference between a loop over an array filled with structs or classes.
public class MyClass
{
public float Value;
}
public struct MyStruct
{
public float Value;
}
// This function is the same for the struct type with "MyStruct[] data"
// as parameter
public void Run(MyClass[] data)
{
for (int i=0; i<data.Length; i++)
{
data[i].Value += 1;
}
}
When you create an array of classes you need to create every single class instance with the new operator. The operating system will decide where every single instance will be the stored in RAM. Most likely some of them will be put into sequential memory location, but others will be stored isolated. You have absolutely no control over this process. Just out of curiosity, I have created an additional test which tricks operating system into placing instances randomly in memory.
MyClass[] myClassArray = new MyClass[arraySize];
int[] positions = new int[arraySize];
for (int j = 0; j < arraySize; j++)
{
positions[j] = j;
}
// Shuffle the positions and use the random list as array indicies
positions = positions.OrderBy(x => Random.value).ToArray();
for (int j = 0; j < arraySize; j++)
{
myClassArray [positions[j]] = new MyClass();
}
The result of the test is displayed in the following chart. The array contained 1 million elements which gives an array size of 4 MB.
Remember: If you test cache misses, a lot of external circumstances like the operating system, threading, and other processes falsify your test result, because they also use the cache.
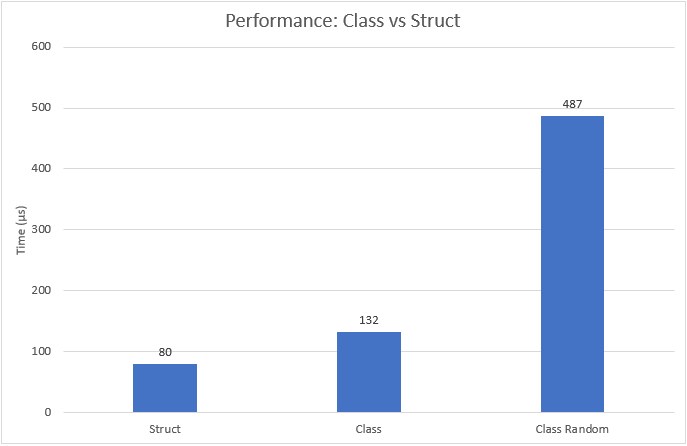
The array of structs is the fastest. The array of classes takes 65% more time. If you shuffle the array, the run-time is even 6 times slower. The results of the tests clearly show how important it is to sequentially access the main memory. The random class test shows how bad your performance can get, if you use random access on your RAM.
Always try to access your memory sequentially to reduce cache misses as much as possible
In this test we iterated over a full array of data accessing every single element. But what happens when you only access every nth-element?
Selective Data Access
In many use-cases you don´t need to access your whole data, but only parts of it. Common use cases are:
- You have big game world and you only want to process entities that are currently visible
- You want to operate on only on a part of your full grid
- You only want to process entities that are selected by the user
- You cut your data into chunks and only want to access a single one
As we have seen in the last test it is important to lay out your data sequentially to avoid random access. In some use-cases this is not possible. The next example will test how different access patterns influences cache misses.
int[] steps = new[] {1, 2, 4, 8, 16, 32, 64, 128, 256}
for (int k = 0; k < steps.Length; k++)
{
int stepSize = steps[k];
int[] arr = new int[32* 1024 * 1024];
for (int i = 0; i < arr.Length; i += stepSize )
{
arr[i] *= 3;
}
}
// This code is a little bit simplified. With bigger step sizes,
// less samples on the array are done, but you can find the
// full source of all experiments in the Appendix.
The code iterates over a huge array of data. In the inner loop the index “i” is incremented by different stepSize instead of accessing always the next element with i++. But how does this affect the cache misses?
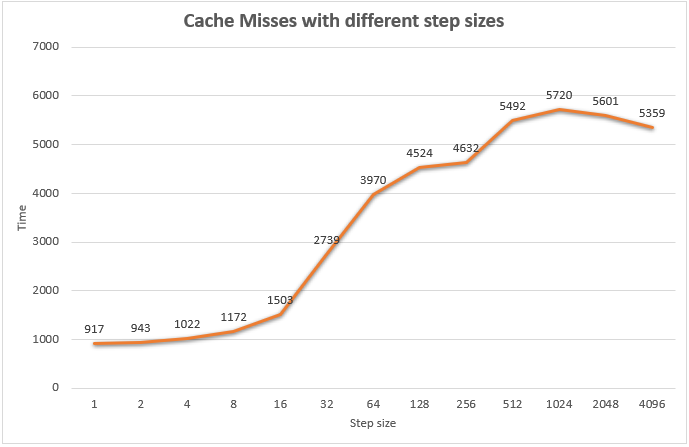
As you can see the bigger the step size, the longer the run-time even if the same number of computations is done. Increasing the step size further would mean fully random access to your memory. What’s interesting is the graph jump between step size 16 and 32. The cache line size is exceeded here (16 * 4 bytes = 64 bytes). With a step size of 32 every data access amounts to a cache miss and the run-time almost doubles from 1503 to 2739.
This is also the reason that if you create a 2-D matrix, it’s row major traversal will be faster than it’s column major traversal. A row is stored in consecutive memory locations and is thus fetched in a cache line.
The last experiment was run on an array of size 32 MB. Let´s check out if the results differ when changing the array size.
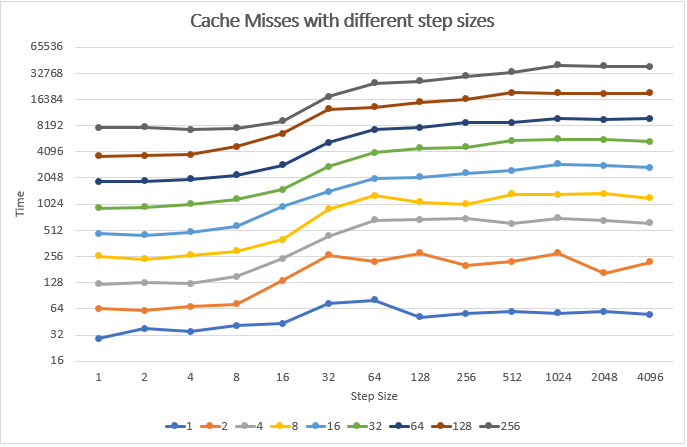
This time the scale on the time axis is logarithmic. Algorithms behaviour on different array sizes is nearly the same. The result is pretty clear!
If you iterate over data and have to skip some of it, you loose speed, because you produce a lot more cache misses. The speed can be up to 6 times slower.
How does this affect object-oriented design?
Object-Oriented vs Data-Oriented data layout
In the next example is shown how data is stored in an object-oriented way compared to a data-oriented.
// The struct defines a sphere in a object oriented way
public struct ObjectOrientedSphere {
Vector3 position;
Color color;
double radius;
};
ObjectOrientedSphere[] objectOrientedSpheres;
// The class defines several spheres in a data oriented way. The data is tightly packed into arrays
public class DataOrientedSphere {
Vector3[] position;
Color[] color;
double[] radius;
};
// Assume you have a list of ObjectOrientedSpheres that you want to move
// every frame by 1
public void MoveObjectOriented(ObjectOrientedSphere[] spheres)
{
for (int i=0; i<spheres.Length; i++)
{
spheres[i].position += 1;
}
}
// This code does the same for the DataOrientedSphere
public void MoveDataOriented(DataOrientedSphere spheres)
{
Point[] positions = spheres.position;
for (int i=0; i<positions.Length; i++)
{
positions[i] += 1;
}
}
The example defines a sphere in two different ways. The ObjectOrientedSphere is defined as you would expect from your daily programmer live. A struct or class contains all the data that the object needs to work. The DataOrientedSphere defines the data in way that you can access the data more efficiently. Instead of storing data per object you only create one object and store the data per value. The important point here is that if you know that you need to access the position data without the color and the radius, you should separate those from each other. You move away from defining logical objects and go into the direction of defining loosely coupled data. In this example the position, color and radius arrays are stored inside of the DataOrientedSphere class, but even this is not necessary. The methods MoveObjectOriented and MoveDataOriented both access the position value to move the sphere and leave the color and radius untouched.
In the top example one sphere has a size of 24 bytes, but lets assume we will vary the size by adding more or less fields. What does this mean for the execution of the “Move” method? The following table shows a benchmark.
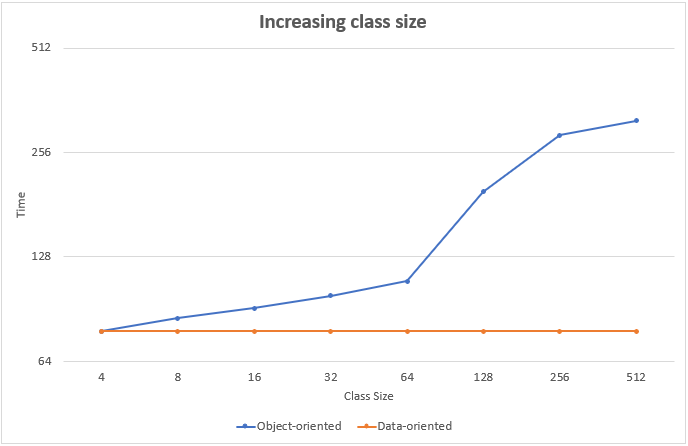
The chart shows that the performance stays constant when you change the size of the data-oriented sphere. The reason for that is obvious, because the other data (color and radius) is stored in other arrays in completely independent memory regions. In contrast the object-oriented sphere is getting slower and slower. While iterating over the array more and more cache misses are produced. It´s interesting to see again the strong performance loss when you exceed the cache line size of 64 byte.
| Object Size | Object Oriented (µs) | Data Oriented (µs) | Ratio |
| 64 | 109 | 78 | 1,4 |
| 128 | 197 | 78 | 2,53 |
Accessing an object with a size of 128 bytes is almost twice as expensive as accessing an object with a size of 64 bytes. The reason for object oriented run-times not being worse than they are is that the CPU is pretty good at predicting which data you might need next.
Storing data in an object-oriented way can reduce your performance by a factor of up to 6, if your objects are getting big
In the previous example and array size of 32 MB was used. Let´s have a look if different array sizes will influence the result.
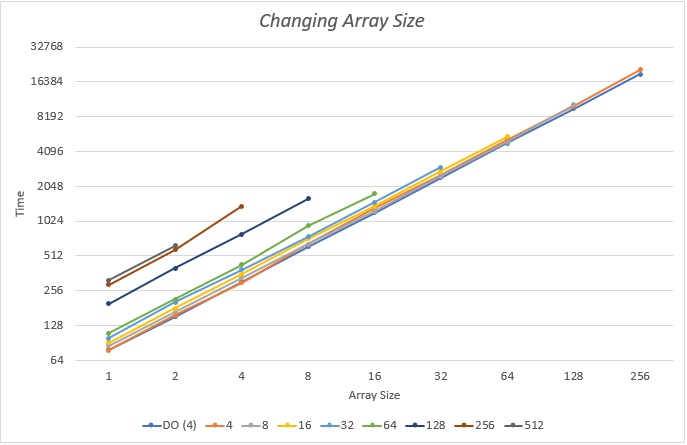
On the vertical axis the array size is marked. The test was run for the data-oriented sphere (marked with DO 4) and the object-oriented sphere with different sizes (marked with 4 – 512). Both axis are logarithmic. As you can see the performance stays linear for all array sizes and class sizes.
Cache Invalidation
What happens when data goes into two different cache locations. e.g. a variable x might be in the L1 cache of core 1 as well as core 2. What will happen when you update that variable?
This situation is known as a data race. It occurs when multiple threads are accessing one location in memory at the same time and at least one of the threads intends to mutate the value. Luckily for us, CPU takes care of this. Whenever a write happens pointing to a memory location in cache, all cache references of the cores to this memory location are invalidated. The other cores have to load that data from the main memory again. However, since data is always loaded in cache-lines, the whole cache-line is invalidated instead of only the changed value.
This creates new problems for multi-threaded systems. When two or more threads try to simultaneously modify bytes belonging to the same cache line, most of the time is wasted into invalidating the cache and reading the updated bytes from the main-memory again. This effect is known as False sharing.
When parallelizing your code, make sure that array-offsets, which threads are using to access memory, are bigger than the cache line size and are aligned to cache lines.
Association to Relational Databases
The thinking behind Data Oriented Design is very similar to how you think about relational databases. Optimizing a relational database can also involve using the cache more efficient, although in this case we are dealing not with a CPU cache but memory pages. A good database designer will also likely split out infrequently accessed data into a separate table rather than creating a table with huge number of columns were only a few of the columns are ever used. He might also choose to de-normalize some of the tables so that data don’t have to be accessed from multiple locations on disk. Just like with Data-Oriented-Design these choices are made by looking at what the data access patterns are and where the performance bottleneck is.
Conclusion
Random access to the main memory is around 6 times slower than sequential access.
Entity-Component-System
The Entity-Component-System follows the data oriented design approach. The main idea of this pattern is to separate your data from your logic. Apart from that it follows the principle of “Composition over Inheritance” to avoid problems that you typically get by inheritance. I`m not going to explain here the general design pattern of ECS, because there are a lot of tutorials about this out there. Instead i will briefly describe how Entities, Components and Systems are defined in Unity and then I plan to have a deeper look into the memory management. Full ECS documentation of Unity can be found here.
Entity
An entity is just an id in comparison to an object-oriented approach where each entity already contains it´s data. This gives you a lot more freedom to model data the way you want.
// Class is provided by Unity
public struct Entity
{
public uint Id;
}
Component
A component contains a set of data. You can attach a component to an entity and make an entity have any combination of components you want. This is the essence of ECS: an entity is simply a collection of components. You’ll notice that no functionality is assumed by any of these components, they’re simply bags of data. The functionality is defined in the system, but more about that in the next section.
// Version 1
public struct WorldObjectData: IComponentData
{
public float3 Position;
public float3 Velocitiy;
}
// Or ...
// Version 2
public struct PositionData: IComponentData
{
public float3 Position;
}
public struct VelocityData: IComponentData
{
public float3 Velocity;
}
You can put several values into one component, if you always have to access them together. If you sometimes only need one value without the other, you should separate them. There are no right or wrong decisions here, the way you model data should depend on your data access patterns.
These are the main rules you have to follow:
- Components have to be structs. As explained in the section above this gives you a controlled memory layout.
- Components have to implement IComponentData. It´s an empty interface that is used as a marker an serves only as generic constraint.
- Can only contain blittable types. This means primitive types, other structs, or enums. This makes sure that all the specified data can be stored inside a struct and no pointers to other heap locations are needed.
- You can use fixed arrays. Therefore you have to mark the struct unsafe. The field declaration looks like this: public fixed int Foo[6]. The compiler knows it´s size at compile time and can inline the array instead of storing it on the heap.
- Classes are not allowed! But why? Remember how a class is stored in memory. It´s lying somewhere on the heap and the struct will contain only a pointer to it. If you access it, you will create a cache miss, because it´s outside of your cache line.
System
A system contains the functionality about one aspect of the game, e.g. a health system would add or remove hit points. Every system defines the components it needs to read and write to. A Movesystem would for example need a PositionComponent and a VelocitiyComponent.
public class VelocitiySystem: ComponentSystem
{
protected override void OnCreateManager()
{
// Init the system here
}
protected override void OnUpdate()
{
// Do your work here
}
}
// The actual implementation is shown later
These are the main rules you have to follow:
- The class has to inherit from ComponentSystem
- In OnCreateManager you can define your dependencies with the help of a ComponentGroup.
- OnUpdate is called every frame. You can query the data from the ComponentGroup and manipulate it
- A ComponentSystem runs synchronously in the main thread
If you want to run your code asynchronously you can use a JobComponentSystem as base class instead. An example will be shown later.
This was just a very brief description of the base patterns of ECS and how Unity implemented those. If you have not understood the principles of ECS completely, you should read Unity´s documentation and some more blogs about that topic. In the next section i will focus again on the memory and how Unity is storing the components.
ECS Memory Layout
The Entity-Component-System adds an abstraction layer between your components and your systems. The layer works a little bit like a database that abstracts the actual memory layout and gives the ability to access and iterate over your data independently of how it is stored. The main idea is that you as developer don´t have to care how the memory is organized, because it´s quite complex. Nevertheless it´s still important to understand what happens under the hood to know which design decisions might have a bad performance impact.
The interface is provided by the EntityManager.
Entity Manager
The EntityManager provides you with the functionality to create, destroy and compose your entities and access the data efficiently. The following code shows how to create new entities.
// An Archetype defines the components an entity has. This one defines
// and object in the game world that can move
EntityArchetype movingObjectArchetype = EntityManager.CreateArchetype(
ComponentType.Create<PositionComponent>(),
ComponentType.Create<MoveComponent>());
// An entity in the game world that is static
EntityArchetype staticObjectArchetype = EntityManager.CreateArchetype(
ComponentType.Create<PositionComponent>());
// Those arrays will store the Id´s (not the data) of the created entities
NativeArray<Entity> movingEntities = new NativeArray<Entity>(10, Allocator.Persistent);
NativeArray<Entity> staticEntities = new NativeArray<Entity>(10, Allocator.Persistent);
// Create 10 new moving entities
EntityManager.CreateEntity(movingObjectArchetype, movingEntities);
// Create 10 new static entities
EntityManager.CreateEntity(staticObjectArchetype, staticEntities);
The code creates twenty entities. All of them have a PostionComponent, but only 10 can move and have a MoveComponent. Let`s see how those are stored in memory.
Chunks and IComponentData
Unity stores the data in chunks. Every chunk contains only data of one single Archetype! Inside of the chunk the data of one Component is stored sequentially. A chunk has a capacity of ~16 KB. If a chunk is full and a new entity of the same archetype is created a new chunk with the same archetype is created.
When running example described above, Unity will create two chunks which will look like this:

Lets imagine every chunk has a capacity of 26 float3 values. The colored boxes symbolize a slot that is used by a component while the grey once are empty. The second line of boxes would directly follow the first line in memory.
Chunk1 has capacity for 13 entities. The available space is equally separated between the MoveComponent and the PositionComponent, because they both need the same size. The data of every component is layed out sequentially for fast iteration with buffer space at the end for the missing three entities. Chunk2 has capacity for 26 entities.
Let´s image one of our static objects is a broken car. What happens if the player can repair it and it should start moving then?
// This is the id of our car Entity carEntity; // Add the component to the car EntityManager.AddComponentData(carEntity, new MoveComponent());
The car which already has the PositionComponent gets additionally a MoveComponent. The “Composition pattern” that is used by ECS is perfectly suitable for those kind of changes. Think about how complicated this would be with Object-Oriented-Design.
But what happens to our memory layout now. One chunk is only allowed to contain one archetype, but our car now changed it´s archetype. Thus the car entity is moved now to the chunk with the movingObjectArchetype. For simplicity reason the car entity has Id 20.The memory will now look like this:

The PositionComponent is copied into the other chunk and the MoveComponent is added.
Now the player hits a tree with the car and the tree entity (with id 13) needs to be destroyed. There is now a gap inside of the data. This is filled by copying the last element there. The memory looks now like this:

Sharing data between entities
Sometimes several entities share the same data. Instead of adding a component to each entity and duplicate it, you can use ISharedComponentData instead.
// Shared data need to implement the ISharedComponentData interface
// instead of IComponentData
public struct SharedData : ISharedComponentData
{
public float SharedValue;
}
SharedData sharedData1 = new SharedData { SharedValue = 2};
SharedData sharedData2 = new SharedData { SharedValue = 5};
// Lets imaging this array contains 6 of our moving objects
Entity[] entities;
for (int i=0; i<entities.Length; i++)
{
// You can assign shared data to an entity like you do with normal
// IComponentData. In this example every second entity gets
// different data than the rest.
EntityManager.AddSharedComponentData(entities[i],
i % 2 == 1 ? sharedData1 : sharedData2 );
}
Shared data is only stored once per chunk. This implies that entities with different shared data cannot be stored in the same chunk. The separation is done by comparing the structs value-based. The first entity from our example has a “SharedValue” of 2 while the second one has 5. Thus they need to be stored in different chunks. But remember we have in total 11 moving elements and 5 of them don´t have the shared data assigned. Those 5 need to be separated from the rest. The chunks look now like this:

Two new chunks are created, one for the shared data value 2 and one for 5. Respectively 3 entities are copied into the new chunks based on the fact that they are odd or even. In the beginning of the chunk the shared component data is stored. Because this needs extra space, the chunk has now capacity for one entity less.
Iterating over data
In the previous chapter we demonstrated how data layout influences iteration speed, but what happens if a system has to iterate over all PositionComponents. They are now split over four chunks. Therefore Unity provides an iterator to easily access data that is split over several chunks. The following code shows the implementation of a system.
public class PositionInitSystem: ComponentSystem
{
private ComponentGroup _componentGroup;
protected override void OnCreateManager()
{
// An entity query defines which components are needed by your
// system
var query = new EntityArchetypeQuery
{
All = new ComponentType[]{ typeof(PositionComponent) }
};
// You can query from the ComponentGroup the data
_componentGroup = GetComponentGroup(query);
}
protected override void OnUpdate()
{
// ComponentDataArray is an iterator that automatically
// calculates the correct memory offsets between chunks when you
// use the [] operator
ComponentDataArray<PositionComponent> positionData =
componentGroup.GetComponentDataArray<PositionComponent>();
// Use the ComponentDataArray like a normal array. The length
// will be 20
for (int i = 0; i < positionData.Length; i++)
{
// The [] operator calculates correct memory location even
// if the data is divided between chunks
positionData[i] = new PositionComponent(new float3(0, 1, 0));
}
}
}
The code above perfectly shows the abstraction layer between your systems and your data. You have actually no idea how the memory is organized and which of your components are stored in which chunk.
Conclusion
In this chapter we have seen how the Entity-Component-System stores the data internally. ECS tries to store components of the same type sequentially in memory. If you have a lot of entities that are composed of different component combination, you segregate components of the same type to a lot of different memory locations. This will produce a lot of cache misses and drop the performance. Thus it´s important to know how a chunk works internally to detect such cases. In some use cases it might even be better to store data outside of ECS with the help of NativeArrays. You can see an example of this in the last chapter.
I just want to mention here some other drawback of ECS:
- ECS is still in preview
- The learning curve is very steep and you constantly run into problems that you can`t solve without looking up solutions on forums or doing hacky workarounds.
- A lot of documentation is missing or even worse – outdated. It´s also hard to find detailed and in depth information on google. You frequently have to post on the Unity forum or check the source code yourself.
- The API is still constantly changing. Features like Injection are getting deprecated and you have to migrate your code.
- Some problems are still not solved like working with strings
- It´s worth to mention that working with grid-based data is absolutely not recommended. ECS will not take care for you that neighbor cells are lying in memory next to each which lets you jump through your memory like a maniac.
2.) Parallelization
Parallelized algorithms with multi-threading is nothing new. It is used since the first multi-core processors were released and there is a lot of documentation out there about the advantages and problems you will run into. If you never used multi-threading before, this chapter might be a little bit rough for you, because I won´t explain any multi-threading basics here.
Without jobs it is not possible in Unity to run your code multi-threaded. You can of course create your own C# thread and manage sync points with Unity’s main thread, but you cannot use any method of the Unity API outside of the main thread.
Job-System
The job system gives you an interface to easily parallelize your code and sync your data with the main thread. Unity`s Job system abstracts the direct thread handling from the developer like the normal C# Tasks or Java Runnables do. Instead of working with threads directly, the job is en-queued at a central scheduler and executed when a thread is available. Unity added three important thinks to the Job-System
- Integration into ECS
- Automatic job dependency management
- Automatic race condition checks
The Job-System is production ready and is used by Unity internally for a lot of heavy work like animations and batching transforms
Jobs and ECS
The job system has an integration into Entity-Component-System. The following code shows the example Unity`s uses in their documentation.
public class RotationSpeedSystem : JobComponentSystem
{
struct RotationSpeedRotation : IJobProcessComponentData<Rotation,
RotationSpeed>
{
public float dt;
public void Execute(ref Rotation rotation,
[ReadOnly]ref RotationSpeed speed)
{
rotation.value = math.mul(math.normalize(rotation.value),
quaternion.axisAngle(math.up(), speed.speed * dt));
}
}
// Any previously scheduled jobs reading/writing from Rotation or
// writing to RotationSpeed will automatically be included in the
// inputDeps dependency.
protected override JobHandle OnUpdate(JobHandle inputDeps)
{
var job = new RotationSpeedRotation() { dt = Time.deltaTime };
return job.Schedule(this, inputDeps);
}
}
Instead of inheriting from ComponentSystem, the JobComponentSystem is the base class now. Inside of the System class the actual Job is defined as struct. The logic which was before implemented in the OnUpdate method, moves now to the Execute-function of the job. There are several interface the job can implement. The easiest one is IJobProcessComponentData. As generic arguments the input types are defined. Unity will then pass into the Execute function the correct data, which is called for every entity once. If you need more control you can use the IJobParralelFor interface. An example for that is defined in the last chapter. The OnUpdate method creates every frame a new instance of the job and schedules it.
Dependency Management
What happens when several system are reading and writing the same data? Lucky for us Unity added an automatic dependency management system. The RotationSpeedSystem system from the previous example updates the RotationComponent. Let`s assume we have a RenderSystem. This will read the current Rotation together with a PositionComponent and maybe a ScaleComponent and renders the object. The RenderSystem can only start, once the RotationSpeedSystem has finished. Otherwise the rotation data is not completely updated. You can define the order in which systems are executed with the three attributes [UpdateBefor], [UpdateAfter] and [UpdateInGroup]. But your jobs that are scheduled and are waiting in queue have to wait of course also for each. This is done by the JobHandle inputDeps. When you schedule a job you can optionally pass in a job handle from another job. If you do, the new job will wait for the other one. You can also combine several handles to a new one, if you have several dependencies. For a JobComponentSystem Unity automatically passes a JobHandle into the OnUpdate function that is initialized with the dependency of your system.
The following code shows how you can manage dependencies outside of ECS.
public struct MyJob : IJobParallelFor
{
// ....
}
MyJob jobA = new MyJob();
MyJob jobB = new MyJob();
// Schedule the job. The second parameter defines on how many elements a
// thread works in sequence. Think about: False Sharing
JobHandle handleA = jobA.Schedule(1000, 64);
// Add the handle of the first job as third argument.
JobHandle handleB = jobB.Schedule(1000, 64, handleA);
// Block until jobB is finished
handleB.Complete();
Automatic race condition checks
Race conditions are one of the most problematic things when you parallelize your code. Because finding and debugging them is such a big pain, Unity created a system that automatically detects any race conditions in DEBUG builds. To make this possible the C# language is heavily restricts. The biggest pain point is, that you are not allowed to use any managed objects (objects that live in the C# world). This completely forbids the use of classes. Instead of C# arrays, NativeArrays from the new Collections API can be used. They are pointers into the C++ heap and need to be disposed manually after they are not needed anymore. The reserved memory is not freed by the C# garbage collector. The last section shows an example how to setup NativeArrays and schedule a job with them.
When you created a race condition, e.g. one thread is writing to an array while another one is reading the data, you will get a run-time error.
Performance Test
The following test will run the example RotationSpeedSystem from above in a job and synchronously in the main thread. This are the result:
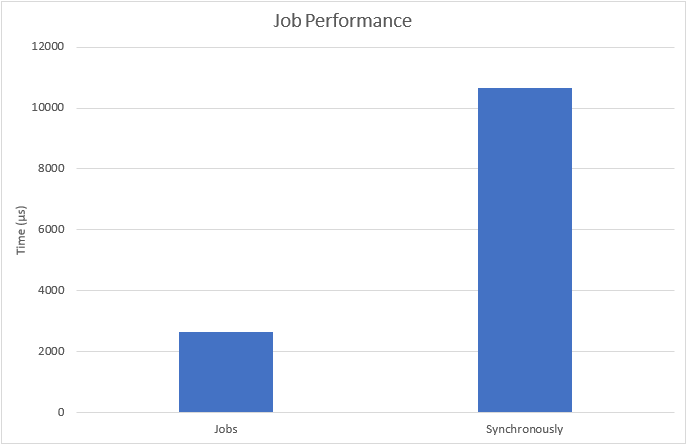
The jobs are around 4 times faster on a processor with 4 cores.
Whenever it´s possible you should parallelize your algorithms to use the full hardware capacity
3.) Compiler optimizations with the Burst-Compiler
At the end of the day, achieving the best possible performance comes down to utilizing the hardware to its fullest. And to do that, you need to optimize your code at the lowest level. That means writing logic in languages like C++, or even C, that can be executed directly on the processor. This opens up the door to some insane optimizations like SIMD instructions, custom assembler. The drawback, besides having to right painfully complex code, is that this approach blocks you from one of Unity’s most important features: the ability to publish your game on multiple platforms. The Burst-Compiler transform your .NET byte-code into highly optimized machine code that is designed to run naively on the processor of your target system and can take full advantage of the platforms you’re compiling for.
Like the Job-System, the Burst-Compiler also heavily restricts the C# language. Managed objects are not allowed (class types and arrays). Instead you can only use blittable data types.
SIMD
The classical processor architecture can process with one instruction exactly one data value. This is called Single-Instruction-Single-Data or SISD. Nearly all compilers especially the mono compiler produces SISD instruction code. But modern CPU´s have an additional instruction set called Single-Instruction-Multiple-Data (SIMD). What does this mean? A single add instruction can sum up several values in one processor cycle.

Because several values are processed at the same time this is also called vectorization. The vector size is mostly 16 or 32.
On desktop computers the additional instruction set is called Streaming SIMD Extensions 4 (SSE4) and has 54 additional operation. It´s widely supported on Intel and AMD processors. The instruction set is hardware dependent. This means that for different target platforms different instruction sets are needed. That is the reason why many compilers (including Mono) do not support SIMD instructions, but that is exactly one key aspect of the Burst-Compiler. It is able to vectorize your for loops to produce more efficient machine code.
Performance Test
// To use the Burst compile you have to add this attribute
[BurstCompile]
public struct JobWithBurst : IJobParallelFor
{
public float Dt;
public NativeArray<Rotation> RotationData;
public NativeArray<RotationSpeed> SpeedData;
public void Execute(int index)
{
Rotation rotation = RotationData[index];
rotation.Value = math.mul(math.normalize(rotation.Value),
quaternion.AxisAngle(math.up(), SpeedData[index].Speed * Dt));
RotationData[index] = rotation;
}
}
This job exists twice, once with [BurstCompile] and once without. Let´s have a look how the performance differs.

The job with the burst compiled code is almost 9 times faster in this example!
4. ) Jobs and Burst without ECS
For existing project it´s mostly impossible to migrate to ECS, but good news for you: The Job System and the Burst Compiler are fully independent of ECS.
It´s possible to move performance heavy code into Jobs. So no worries you can still get full performance without ECS, because ECS is not the reason why your game is getting faster. The big change is to switch from an Object-Oriented-Design to Data-Oriented-Design besides from using the Job-System and the Burst-Compiler. ECS perfectly implements Data-Oriented-Design and gives you a clean interface to work on your data. Therefore ECS adds an extra layer between the actual data (Components) and your logic (Systems). This gives a lot of flexibility, but like every abstraction layer also adds some performance overhead. If you don´t need ECS for your use case or you can´t migrate your code, you can still use the rest of tech stack and have the same or even better performance by storing your data directly in NativeArrays. The only thing you have to do: Think and program data-oriented.
The following example will show a simple setup of a job without ECS.
[BurstCompile]
public struct Job : IJobParallelFor
{
[ReadOnly]
public NativeArray<IsometricCoordinateData> IsometricCoordinates;
[ReadOnly]
public NativeArray<HeightData> Heights;
public NativeArray<TemperatureData> Temperature;
public void Execute(int index)
{
float iso = IsometricCoordinates[index].IsometricCoordinate.x / 90
float alpha = 1 - math.abs(iso);
float height = 1- Heights[index].Height;
CellAirTemperatureData airTemperature = Temperature[index];
airTemperature.Temperature = alpha * height;
Temperature[index] = airTemperature;
}
}
The job calculates a relative temperature between 0 and 1 on a planet based on the distance to the equator and the height. It spreads the work on several CPU-Cores. The following code will setup and run the job.
int cellCount = 100000;
// Create NativeArray arrays to store your data
NativeArray<IsometricCoordinateData> isometricCoordinateData =
new NativeArray<IsometricCoordinateData>(cellCount, Allocator.TempJob);
NativeArray<HeightData> heightData =
new NativeArray<HeightData>(cellCount, Allocator.TempJob);
NativeArray<TemperatureData> temperatureData =
new NativeArray<TemperatureData>(cellCount, Allocator.TempJob);
// Fill with data...
// You can also use Allocator.Persistance if you only want to fill the
// arrays once and reuse it every frame
// Create a new job and assign the data
var job = new Job
{
Temperature = temperatureData,
IsometricCoordinates = isometricCoordinateData,
Heights = heightData
};
// Put the job into the queue
var jobHandle = job.Schedule(cellCount, 32);
// You don´t need to call Complete() directly after schedule, because it
// will block the main thread. Instead call it when you actually need
// the result
jobHandle.Complete();
// You need to dispose arrays manually, because they are not managed by
// the garbage collector
isometricCoordinateData.Dispose();
heightData.Dispose();
temperatureData.Dispose();