
Introduction
Big Data has had an interesting history of evolution at InnoGames; from crons and shell scripts generating reports from data in a Relational Database Management System (RDBMS), to the Hadoop stack that is at the core of our Big Data infrastructure today. It is understandable why Hadoop was the technology of choice, more than 10 years ago, with InnoGames embracing open source technologies since it’s inception, but also the “doing it yourself” approach with using our on-premise infrastructure and expertise. At the time there were two major open source and free Hadoop distributions which had good communities and support; Cloudera Distributed Hadoop (CDH) from Cloudera and Hortonworks Data Platform (HDP) from Hortonworks. In the end it was decided to go with the Cloudera CDH 4 distribution that was available at that point in time. The general architecture of our Big Data infrastructure has not changed that much over the years, in particular Hadoop remained our Data Lake technology, utilizing the following core components:
- HDFS as the storage layer
- YARN as the resource management and data processing layer
- Hive as the data warehouse layer
Even though a lot of other components in our Big Data infrastructure have been either removed, replaced or new components added over the years; the three core components listed above still remain a central part to this day. An overview of our Big Data infrastructure can be seen in the following graphic (credit Volker Janz).
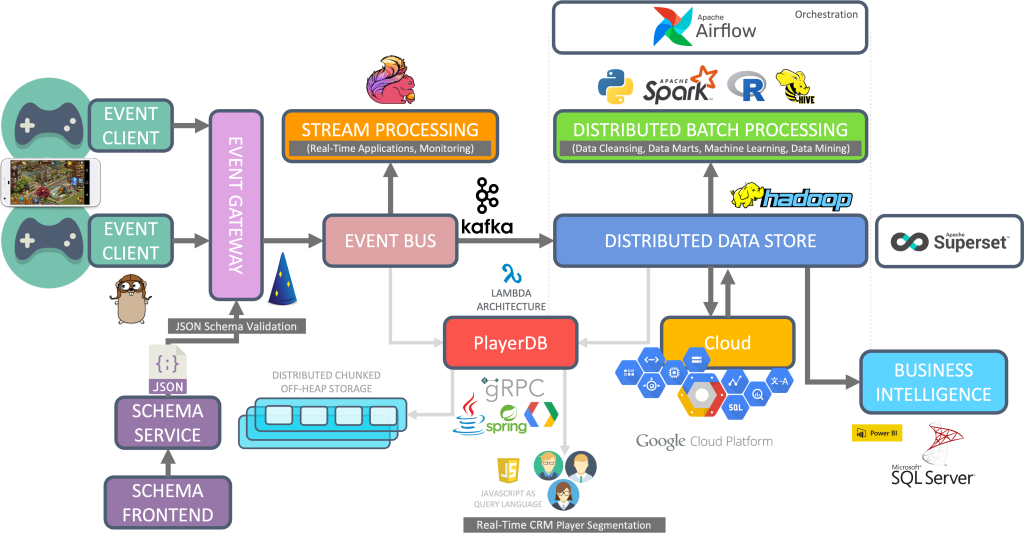
The main data source for us are player interactions with our game products in the form of events, each event representing a JSON encoded interaction with metadata. This architecture allows us, at present, to process more than 1.5 billion events per day, with over 300 batch ETL jobs, while also serving real-time queries of users from various departments that rely on data; all running on our relatively small Hadoop cluster (less than 100 nodes in 4 environments/clusters). But Hadoop itself being a distributed, highly scalable system, which scales up to tens of thousands of nodes; provides us with the reassurance we need to be able to easily scale up, should the need ever arise. As far as cluster deployment and configuration management is concerned, we opted against using Hadoop cluster management software such as Ambari or Cloudera Manager, but instead went with using the tools we already had at our disposal for managing our infrastructure; namely Puppet and our own in-house built ServerAdmin.
Using the Cloudera CDH distribution served us well over the years, and it was especially beneficial for the Data Infrastructure team to have access to Cloudera’s Debian repositories with pre-built packages. Cloudera also regularly applied patches and bug fixes for the various components even before new versions of said components were released in upstream projects. But the “good” times with Cloudera CDH were soon to be over…
Why migrate?
At the start of 2019, there was a big announcement about the merger of the two major free Hadoop distribution providers: Cloudera and Hortonworks into what is today only Cloudera. As these two companies held the majority share of the market for providing free Hadoop distributions; it was obvious to see where this was going, with them now having almost a monopoly on the market for providing Hadoop to companies that relied on on-premise solutions. Soon enough, communities’ worst fears would come to be realized; the monetization model of Cloudera would change from selling premium support and proprietary tools to it’s customers, to implementing a licensing model for their Hadoop distribution as well as switching from on-premise focused CDH to the more cloud orientated CDP distribution. This meant that all the freely available repositories and packages for CDH and HDP would be moving behind a paywall.
At the time (year 2020) when we were evaluating the impact this would have for us, we estimated that if we were to switch from running CDH 5 to CDP and had to pay the licensing fees; it would amount to something close to the purchase cost of our hardware that we were running Hadoop on, per year. So obviously this would be a major cost overhead, and would also go against our philosophy of using freely available open source software, whenever possible. Another major issue for us was that Cloudera had dropped support for Debian, even in CDH 6. And since all our systems are running on Debian, it would introduce even more work and problems for us, if we would now have to have a separate setup for our Hadoop cluster running on a different Linux distribution, rewriting a huge chunk of our Puppet manifests and deployment processes.
Our CDH 5 was already EOL for quite some time, and upgrading was a necessity for reasons of security, bug fixes, performance improvements and new features which our stakeholders were craving for. And since Cloudera was no longer an option for us, for the reasons mentioned above, we had to start looking for a replacement that would fit our needs and be as future-proof as possible.
Choosing a replacement distribution
The criteria we set for a replacement distribution were:
- freely available and open source
- provides pre-built (or easy to self build) Debian packages
- supports on-premises deployment
- actively developed and supported by the community
There were a few Cloud solutions such as AWS EMR, Databricks, Snowflake, Azure HDInsights, all of which would increase our operational costs, and also impose a complete paradigm shift in regards to how we view and run our infrastructure. The only available project that fit all of our criteria was Apache Bigtop. As the description of the project says “Bigtop is an Apache Foundation project for Infrastructure Engineers and Data Scientists looking for comprehensive packaging, testing, and configuration of the leading open source big data components“, and is exactly what we were looking for. The most important part of the CDH distribution that we used; was the availability of pre-built Debian packages, and Hadoop components that were tested to work together across the whole stack. Configuration and deployment was already managed by us, so Apache Bigtop would fit perfectly for our needs.
The one thing we were losing, when comparing Cloudera CDH to Apache Bigtop, were the patches and bug fixes that Cloudera would apply in very frequent minor version releases. The release schedule for Apache Bigtop was longer, and minor bug fix releases rarer. But, with Apache Bigtop being fully open source, we have the opportunity to relatively easily build any of the components ourselves from the Bigtop Github repository. This feature was used by us to apply patches to ie. Hive for the bugs that we encountered during the migration process such as HIVE-22757, HIVE-20210 and similar. One last thing of concern for us, that we had to tackle, was the replacement of some Hadoop components in the CDH distribution, that were not present in Apache Bigtop.
Finding suitable replacements for some Cloudera CDH components
There were some components in the CDH distribution that were primarily developed and contributed to, by Cloudera; which served important roles in our Data infrastructure. Before embarking on our migration journey, we had to find viable replacements that would serve the same purpose, while naturally fitting the same criteria of: freely available open source software that is actively developed and supported by the community.
Hue
One such component was Cloudera’s Hue, being a web interface for running SQL queries on various databases and data warehouses, in our case being exclusively used to query Hive. We contemplated building our own Hue from source, since it is a project that is still under the Apache License and open source, and our users were so used to it and it’s interface. But at the same time we also really wanted to move away from Cloudera, having had this bad experience with their paywalls and monetization practices. And Hue being mostly developed and contributed to by Cloudera, made us look for an alternative. The tool that could fulfill this task was found in Apache Superset, more of a data exploration and visualization tool, but it’s main use case for us would be it’s SQL editor.
Impala
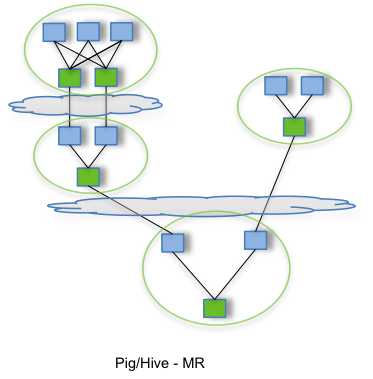
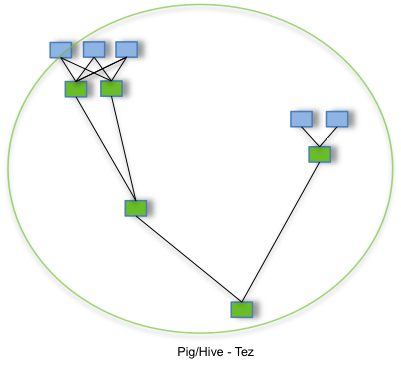
Even though Apache Impala is supposed to be used as a fast, low latency query engine; we were really not utilizing it as such, but it was instead used for batch processing in our Business Intelligence (BI) system. With the new Apache Tez data processing framework, based on directed acyclic graphs (DAG), promising significant optimizations and performance gains over MapReduce (which was our default Hive execution engine in CDH 5), we were confident that we could replace Impala with Hive on Tez for our BI use-case, without impacting the SLA. This would also prove to be true during performance testing on our first Bigtop POC cluster. We could also provide the low-latency query engine through Hive LLAP, should the need arise.
Apache Sentry
Our role based authorization service for accessing the data warehouse through Hive was Apache Sentry; while the authentication is done through Lighweight Directory Access Protocol (LDAP). Since Sentry was becoming a deprecated project, even in Cloudera’s newest distribution, it was replaced with Apache Ranger. Ranger is the de-facto standard for security, authorization and auditing across the whole Hadoop ecosystem. It has a very nice web interface for managing policies, accessing audit logs, managing users and groups and etc., but what really makes it great is the REST API, which allows us to automate and manage Ranger with Puppet. There is also a handy usersync tool, which allows syncing of users and groups from Active Directory (AD) or LDAP to Ranger.
Migration process
Setting up the PoC cluster
Having done all the theoretical preparations and research, that convinced us that migrating from CDH 5 to Bigtop 1.4 would be possible; it was time to put it to the test. Our plan was to first set up a Proof of Concept cluster; that would involve all the components required for us to run our tests and prepare all the Puppet manifests with updated configurations as well as creating new manifests for newly introduced components such as YARN Timeline server, Ranger and etc. Besides the aforementioned component replacements, the following were to be additionally replaced or upgraded:
- Hadoop 2.6.0 to 2.8.5
- Spark 1.6.0 to 2.2.3
- Hive 1.1.0 to 2.3.3 (including Metastore and HiveServer2)
- Default Hive execution engine from Mapreduce to Tez
- Default Hive tables file format from parquet to ORC
With some changes and additions to our existing CDH Puppet manifests, we could get our PoC Bigtop 1.4 cluster deployed and configured with Puppet. Having had a few small bumps along the road, such as adding some missing Spark jars to the Hive classpath for being able to run Hive on Spark; we were eventually able to get our PoC cluster up and running from scratch. Besides adding the new Timeline server specific configurations in yarn-site.xml, most of the core-site.xml and hdfs-site.xml configurations were still applicable. The relevant configuration snippets for Tez and the YARN Timeline server are listed below:
yarn-site.xml Timeline server config example
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.version</name>
<value>1.5</value>
<description>Timeline service version we’re currently using.</description>
</property>
<property>
<name>yarn.timeline-service.store-class</name>
<value>org.apache.hadoop.yarn.server.timeline.EntityGroupFSTimelineStore</value>
<description>Main storage class for YARN timeline server.</description>
</property>
<property>
<name>yarn.timeline-service.entity-group-fs-store.active-dir</name>
<value>/ats/active/</value>
<description>DFS path to store active application’s timeline data</description>
</property>
<property>
<name>yarn.timeline-service.entity-group-fs-store.done-dir</name>
<value>/ats/done/</value>
<description>DFS path to store done application’s timeline data</description>
</property>
<property>
<name>yarn.timeline-service.entity-group-fs-store.summary-store</name>
<value>org.apache.hadoop.yarn.server.timeline.RollingLevelDBTimelineStore</value>
<description>Summary storage for ATS v1.5</description>
</property>
<property>
<name>yarn.timeline-service.entity-group-fs-store.group-id-plugin-classes</name>
<value>org.apache.tez.dag.history.logging.ats.TimelineCachePluginImpl</value>
</property>
<property>
<name>yarn.timeline-service.leveldb-timeline-store.path</name>
<value>/var/lib/hadoop-yarn/timeline</value>
</property>
We also need Tez specific configuration options for tez-site.xml and hive-site.xml:
tez-site.xml
<configuration>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.75</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>tez.am.java.opts</name>
<value>-XX:ParallelGCThreads=2</value>
</property>
<property>
<name>tez.runtime.io.sort.mb</name>
<!-- Should be 40%-->
<value>1638</value>
</property>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/apps/tez/,${fs.defaultFS}/apps/tez/lib/</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.dag.history.logging.enabled</name>
<value>true</value>
</property>
<property>
<name>tez.am.history.logging.enabled</name>
<value>true</value>
</property>
<property>
<description>Enable Tez to use the Timeline Server for History Logging</description>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSV15HistoryLoggingService</value>
</property>
<property>
<description>Time in ms to wait while flushing YARN ATS data during shutdown.</description>
<name>tez.yarn.ats.event.flush.timeout.millis</name>
<value>300000</value>
</property>
<property>
<name>tez.grouping.min-size</name>
<value>16777216</value>
</property>
<property>
<name>tez.grouping.max-size</name>
<value>1073741824</value>
</property>
<property>
<name>tez.am.container.reuse.enabled</name>
<value>true</value>
</property>
<property>
<name>tez.session.am.dag.submit.timeout.secs</name>
<value>300</value>
</property>
<property>
<name>tez.am.container.session.delay-allocation-millis</name>
<value>300000</value>
</property>
</configuration>
hive-site.xml
<property>
<name>hive.tez.container.size</name>
<value>4096</value>
</property>
<property>
<name>hive.tez.input.format</name>
<value>org.apache.hadoop.hive.ql.io.HiveInputFormat</value>
</property>
<property>
<name>hive.tez.auto.reducer.parallelism</name>
<value>false</value>
</property>
<property>
<name>hive.tez.min.partition.factor</name>
<value>0.25</value>
</property>
<property>
<name>hive.tez.max.partition.factor</name>
<value>2.0</value>
</property>
<property>
<name>tez.counters.max</name>
<value>1000</value>
</property>
<property>
<name>hive.tez.java.opts</name>
<value>-Xmx3072M -XX:ParallelGCThreads=2</value>
</property>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/apps/tez/,${fs.defaultFS}/apps/tez/lib/</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive_timeline_logging_enabled</name>
<value>true</value>
</property>
<property>
<name>hive.default.fileformat</name>
<value>ORC</value>
</property>
With all that, we were able to create a few Hive tables and get some data on the PoC cluster to run some test queries on the new Hive execution engine Tez. Next step would be to test the upgrade procedure for an in-place upgrade of a live cluster.
Upgrading the staging cluster
Setting up the PoC cluster from scratch was relatively easy, but we still didn’t know how it would work when upgrading and existing CDH cluster running Hadoop 2.6.0 to Bigtop’s Hadoop 2.8.5. Unfortunately, there were no step-by-step guides available for such a migration, so we had to fall back to the official Hadoop documentation on performing a Rolling upgrade on a HA (highly-available) cluster. This also provided a backout option with the ability to revert and downgrade, albeit with data loss for anything that was written to HDFS since the fsimage (snapshot of the Namenode metadata) was created during the rolling upgrade procedure. The upgrade on the staging cluster went pretty smoothly, and we were now able to test our whole event-pipeline and majority of the ETL jobs on our staging environment.
Some Hive tuning, and ETL job adjustments later, and we were able to run everything on the Bigtop staging cluster, as before with CDH; with some noticeable performance improvements for certain ETL jobs and queries. Satisfied with the results, our next step and big unknown; how would this all translate to the production cluster and environment?
Upgrading the production cluster
With the staging cluster upgrade procedure documented, and a step-by-step upgrade plan in place, we could now proceed with the production cluster. The question that was still hanging in the air; how will the new Bigtop cluster perform and what kind of issues may arise from it? Keeping in mind, that the PoC and staging cluster upgrades served their purpose for preparing all the necessary configurations and tuning for their size; but for comparison, the staging cluster has around 3TB of data while the production cluster holds 2.6PB of data. There was no way for us to be 100% certain that using the current configuration, all our business critical jobs would work flawlessly when scaled up to the production data size. Quite the opposite, we planned with having to do some adjustments and tuning to be able to have all our jobs and systems running as before, or better. But the thing that we were quite confident in, was that we had a good upgrade plan and procedure in place, that was proven on both the PoC and staging clusters.
Sure enough, following the upgrade procedure we had in place, things went very smoothly, and we could finish the upgrade process on the production environment in a couple of hours. When the time came to enable our first and most important ETL jobs, that is when we first noticed performance issues and failures on various jobs. Tuning options such as hive.tez.container.size, hive.exec.reducers.max, hive.exec.reducers.bytes.per.reducer and similar, we could get a lot of improvements and fixing some jobs. However, one important ETL job, that serves as a starting point for most of our other ETL jobs, was having issues with performance. It is an hourly job that integrates the raw JSON events, written to HDFS by Flink, into our Operational Data Store (ODS) layer; and it is imperative that this job finishes in under an hour, for the whole ETL jobs chain to function properly. Unfortunately, this was not the case, and we had inconsistencies with it’s runtime going over an hour at times.
A few sleepless nights of trying various tuning options and investigation later, we were finally able to pinpoint the culprit: the output of our integration job were many small files, smaller than our configured HDFS block size of 128MB, and this severely degraded the performance of queries on the resulting table. The solution was to enable hive.merge.tezfiles=true, and this configuration option alone solved most of our performance issues. Now that the production cluster was performant again for our batch ETL jobs, we could make it available for the stakeholders for interactive queries and similar use-cases. Over the course of the next weeks and months, we would occasionally come up on some issues or bugs like ie. with Hive (previously mentioned HIVE-22757, HIVE-20210), which we could fix by applying patches and building our own packages with the provided Bigtop scripts and tools.
Conclusion
Our journey from CDH to Bigtop was at times a bit thorny, but overall it was a success, that fulfilled all of our goals that we set before we embarked on that journey. It has proved itself as sustainable for the future, as we have since also upgraded to Bigtop 1.5, and are in the process of upgrading to Bigtop 3.2; which is a major Hadoop version upgrade from 2.x to 3.x. But there were also painful lessons that were learned; such as the need to have a production-sized testing cluster, that would serve as an intermediary step between staging and production in all our future upgrade processes. Where we can carry out functional and performance tests, without any risk of impacting live operations and significantly reducing risk of bad outcomes of future production cluster upgrades.
During a hardware upgrade on the production cluster, we repurposed the old hardware to create a dedicated testing environment, mirroring the data and processes of the production environment. It has not only proven itself invaluable for our Bigtop upgrade process, but also provided stakeholders with a safe space to test ETL jobs without posing any risk to live operations and data. Even as we move towards a hybrid data infrastructure setup, with combining our on-premises architecture with cloud components based on Google Cloud Platform (GCP); we still maintain the Hadoop stack at the core, now powered by Apache Bigtop.