Introduction
For a long time already, it has been clear that software development is more than just a job. More than coding something that somehow works. It is about craftsmanship and the responsibility to deliver working software in a good quality. Robert C. Martin definitely influenced – if not started – the movement of developers pushing our craft with his books about Clean code. Many articles and many people have since then discussed the benefits of applying this techniques in our field of work. Probably as long there are discussions going on what Clean code does to our software’s performance. It is an ongoing battle of Clean code vs. performance. For many people the performance aspect is an easy excuse to not write clean code – regardless of the other clear benefits you get from applying clean-code techniques. This article is a very little case-study that stands against this more or less persistent opinion and hopefully shows that these two things don’t need to be mutually exclusive.
Scenario
At InnoGames our server applications are continuously load-tested in order to avoid performance problems before we release something to our players. Unfortunately, we can not always foresee how players play our games. In fact, they often come up with very interesting ways to play the game and every user has its very own play style. While this is a challenging aspect for coming up with a performance model, for me this is also one of things I love about game development. Our players challenge me to have a more in-depth view on the applications I craft in order to anticipate better when a performance problem occurs. This includes knowledge about potential frameworks and knowledge about the internals of our environment. And as I’m mostly developing with Java and Spring-Boot these days I’m also interested in compiler behaviour and try to understand what the JIT compiler of Java is doing.
Fortunately, for the latter there are some additional JVM options you can enable in order to get a glimpse on what’s going on:
- -XX:+UnlockDiagnosticVMOptions – unlock diagnostic features
- -XX:+PrintCompilation – shows diagnostic output when compilation happens
- -XX:+PrintInlining – shows the decisions around inlining made by the VM
For example you could startup your application like this:
java -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -jar yourapplication.jar > inlining.log
You probably want to pipe the output to some file as this gets quite messy, quite fast. And it also helps to analyze the output later without getting a headache.
So I did the above with one of our Spring-Boot based games and noticed the following reoccuring outputs:
... @ 8 org.springframework.util.ObjectUtils::nullSafeEquals (337 bytes) hot method too big ...
What you see here is that a hot (frequently called) method of the Spring-Framework is obviously too big for something. For the sake of this article, I won’t go into too much detail here, but in a nutshell the 337 bytes are higher than the default of 325 on our x86 systems and prevent the compiler from doing method inlining. (For the very interested of you, you can look into the OpenJDK source code at the following two places though)
- http://hg.openjdk.java.net/jdk/jdk/file/1caf2daef7cf/src/hotspot/cpu/x86/c2_globals_x86.hpp#l47
- http://hg.openjdk.java.net/jdk/jdk/file/1caf2daef7cf/src/hotspot/share/opto/bytecodeInfo.cpp#l168
Inlining basics
Even though we don’t go into too much detail, the term inlining already came up several times. So let’s just shortly explain what inlining is in our context.
Let’s say that you have a method invocation in your pseudo-code:
// actual callsite somewhere in your code
doAllTheThings();
//...
function doAllTheThings() {
doThings();
doSomeMoreThings();
}
When a method is being “inlined” the body of the method is taken and replaces the actual invocation of the method. Essentially the compiler will produce this if he inlines doAllTheThings():
// previous callsite of doAllTheThings() doThings(); doSomeMoreThings();
By doing so, the compiler can actually avoid the overhead of calling doAllTheThings() altogether. For example, this saves the cost of creating stack frames and alike that usually come along with method invocations. Obviously, this duplicates the method body of doAllTheThings() and is thus not for free. The JVM has some measures it applies in order to not inline everything that is theoretically available for inlining. Think about big methods where a duplication of the body would hurt more than it helps. For example, duplicating bigger method bodies might hurt instruction cache performance in the end as the executed code doesn’t fit in the lower level caches anymore. To be entirely honest, there is so much going on that I personally find it hard to even scratch the surface of it. I’m glad that the JVM is so sophisticated to balance this for us.
The nice side-effect of inlining though – I should probably say the biggest effect – is the fact that it opens the possibility for further optimizations to kick in. By “broadening” the code some optimizations can be applied more effectively as well.
Assumption
Coming back to the performance and clean code aspect, we can come up with the following interesting assumption based on the inlining basics mentioned earlier:
Theoretically, one should be able to have less method invocations by introducing more smaller – and thus cleaner – methods and therefore more methods.
Prove the assumption
The method we saw earlier in the compilation logs – more specifically ObjectUtils::nullSafeEquals() of the Spring-Framework – looked like this before I worked on it:
public static boolean nullSafeEquals(Object o1, Object o2) {
if (o1 == o2) {
return true;
}
if (o1 == null || o2 == null) {
return false;
}
if (o1.equals(o2)) {
return true;
}
if (o1.getClass().isArray() && o2.getClass().isArray()) {
if (o1 instanceof Object[] && o2 instanceof Object[]) {
return Arrays.equals((Object[]) o1, (Object[]) o2);
}
if (o1 instanceof boolean[] && o2 instanceof boolean[]) {
return Arrays.equals((boolean[]) o1, (boolean[]) o2);
}
if (o1 instanceof byte[] && o2 instanceof byte[]) {
return Arrays.equals((byte[]) o1, (byte[]) o2);
}
if (o1 instanceof char[] && o2 instanceof char[]) {
return Arrays.equals((char[]) o1, (char[]) o2);
}
if (o1 instanceof double[] && o2 instanceof double[]) {
return Arrays.equals((double[]) o1, (double[]) o2);
}
if (o1 instanceof float[] && o2 instanceof float[]) {
return Arrays.equals((float[]) o1, (float[]) o2);
}
if (o1 instanceof int[] && o2 instanceof int[]) {
return Arrays.equals((int[]) o1, (int[]) o2);
}
if (o1 instanceof long[] && o2 instanceof long[]) {
return Arrays.equals((long[]) o1, (long[]) o2);
}
if (o1 instanceof short[] && o2 instanceof short[]) {
return Arrays.equals((short[]) o1, (short[]) o2);
}
}
return false;
}
It is a fairly big method that is hard to grasp at first sight. Although not very complex it is still too big to be considered clean if you ask me. And one could argue that it does two things: It compares objects and arrays. As we couldn’t split this in two separate APIs in the Framework to stay compatible and don’t break too much for other people, I decided to at least improve it. To also prove the assumption that more smaller and cleaner methods can actually allow the compiler to inline the method I made a small improvement by simply extracting the more uncommon use-case of checking for array equality:
public static boolean nullSafeEquals(Object o1, Object o2) {
if (o1 == o2) {
return true;
}
if (o1 == null || o2 == null) {
return false;
}
if (o1.equals(o2)) {
return true;
}
if (o1.getClass().isArray() && o2.getClass().isArray()) {
return checkForArrayEquality(o1, o2);
}
return false;
}
private static boolean checkForArrayEquality(Object o1, Object o2) {
if (o1 instanceof Object[] && o2 instanceof Object[]) {
return Arrays.equals((Object[]) o1, (Object[]) o2);
}
if (o1 instanceof boolean[] && o2 instanceof boolean[]) {
return Arrays.equals((boolean[]) o1, (boolean[]) o2);
}
if (o1 instanceof byte[] && o2 instanceof byte[]) {
return Arrays.equals((byte[]) o1, (byte[]) o2);
}
if (o1 instanceof char[] && o2 instanceof char[]) {
return Arrays.equals((char[]) o1, (char[]) o2);
}
if (o1 instanceof double[] && o2 instanceof double[]) {
return Arrays.equals((double[]) o1, (double[]) o2);
}
if (o1 instanceof float[] && o2 instanceof float[]) {
return Arrays.equals((float[]) o1, (float[]) o2);
}
if (o1 instanceof int[] && o2 instanceof int[]) {
return Arrays.equals((int[]) o1, (int[]) o2);
}
if (o1 instanceof long[] && o2 instanceof long[]) {
return Arrays.equals((long[]) o1, (long[]) o2);
}
if (o1 instanceof short[] && o2 instanceof short[]) {
return Arrays.equals((short[]) o1, (short[]) o2);
}
return false;
}
After doing another debug-run with the JVM options mentioned in the beginning the log showed this:
... @ 8 com.innogames.benchmark.ObjectUtilsInlinedEquals::nullSafeEquals (55 bytes) inline (hot) ...
Okay – great, right? I could reduce the cyclomatic complexity of the method and therefore made it cleaner. And apparently the VM is also more happy with it.
Writing a benchmark
Just looking at compilation logs does not prove that this code change made your code faster. Of course, you want to profile performance improvements with a dedicated benchmark. The times of doing micro-benchmarks by measuring the elapsed time between your tested code are long gone and actually most of the time not reliable (enough). The JIT compiler is a smart beast that does Dead-Code-Elimination, Loop-Unrolling, Inlining, Constant-Folding and many other more or less complex optimizations that will screw with your test-results when you simply measure performance with e.g System.currentTimeMillis(). You should use a framework for that purpose, which the OpenJDK fortunately delivers with JMH. There are a bunch of examples to get you started with writing microbenchmarks, so I won’t go into that and jump to the little benchmark I did:
@BenchmarkMode(Mode.Throughput)
@State(Scope.Thread)
@Warmup(iterations = 10)
@Fork(value = 2)
public class Benchmark {
@State(Scope.Thread)
public static class TestState {
public String firstString = "firstString";
public String secondString = "secondString";
public String[] firstStringArray = new String[] {"a", "b", "c"};
public String[] secondStringArray = new String[] {"a", "b", "c"};
public List<String> firstStringCollection = Arrays.asList("a", "b", "c");
public List<String> secondStringCollection = Arrays.asList("a", "b", "c");
}
@Benchmark
public boolean testString(TestState testState) {
return ObjectUtilsNonInlined.nullSafeEquals(testState.firstString, testState.secondString);
}
@Benchmark
public boolean testStringInlined(TestState testState) {
return ObjectUtilsInlined.nullSafeEquals(testState.firstString, testState.secondString);
}
@Benchmark
public boolean testStringArray(TestState testState) {
return ObjectUtilsNonInlined.nullSafeEquals(testState.firstStringArray, testState.secondStringArray);
}
@Benchmark
public boolean testStringArrayInlined(TestState testState) {
return ObjectUtilsInlined.nullSafeEquals(testState.firstStringArray, testState.secondStringArray);
}
@Benchmark
public boolean testStringCollection(TestState testState) {
return ObjectUtilsNonInlined.nullSafeEquals(testState.firstStringCollection, testState.secondStringCollection);
}
@Benchmark
public boolean testStringCollectionInlined(TestState testState) {
return ObjectUtilsInlined.nullSafeEquals(testState.firstStringCollection, testState.secondStringCollection);
}
}
I’m basically testing Spring’s unchanged ObjectUtils.nullSafeEquals() against my changed version of it.
Results
The results of this microbenchmark look roughly like this:
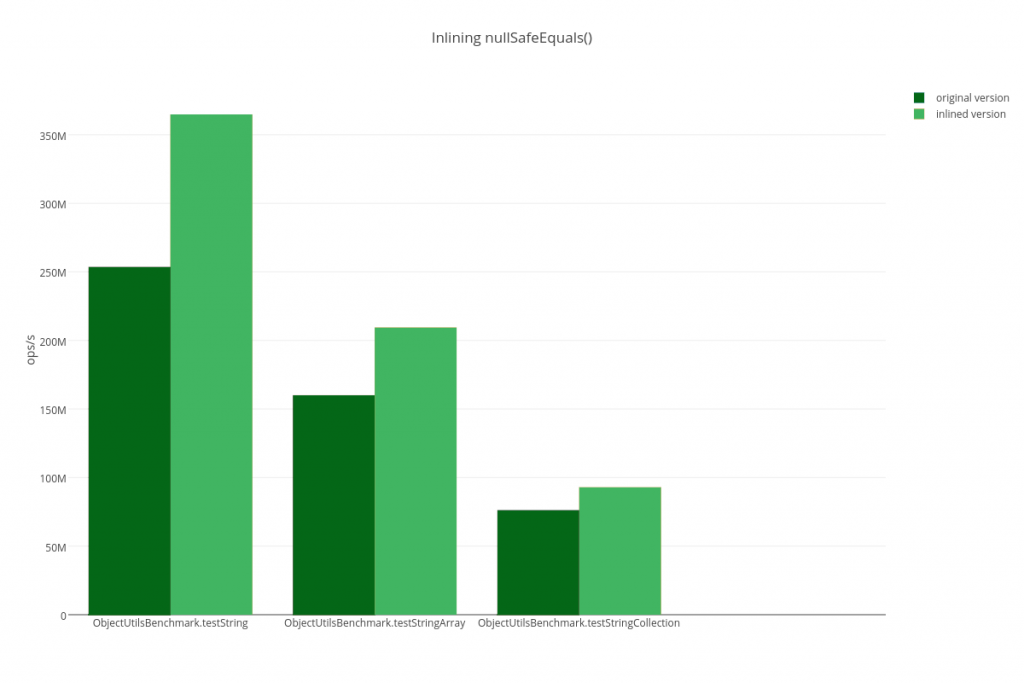
Benchmark Mode Score Errors Units Benchmark.testString thrpt 253465802,704 ± 3371730,543 ops/s Benchmark.testStringInlined thrpt 364743912,814 ± 1970639,774 ops/s Benchmark.testStringArray thrpt 159936357,303 ± 1407612,433 ops/s Benchmark.testStringArrayInlined thrpt 209394797,278 ± 1832786,161 ops/s Benchmark.testStringCollection thrpt 76125444,208 ± 405324,003 ops/s Benchmark.testStringCollectionInlined thrpt 92899228,255 ± 2400986,775 ops/s
You will notice that the inlined versions are indeed faster than their non-inlineable counterparts as they allow more operations per second. Even the more uncommon use-case of array equality got faster – even though I extracted this functionality into its own method. To be honest, with the error margin for collections it could be a draw for those, but after running the benchmark on several machines it always showed higher throughputs for the inlined version.
Notes
The decision of when and how a method is inlined is actually a “bit” more complicated and by far not that easy as described in the “Inlining basics” section. The compiler could for example even change its mind about the hotness of the method and won’t inline the method anymore. Keep in mind that we’re talking about just-in-time compilation which can change over the runtime of the application. In our case the compiler probably won’t change its mind because it’s a static method and it can’t be overridden – which is an additional measure the JIT compiler takes into account when he wants to inline stuff. Static methods are statically bound, which means that the JIT compiler doesn’t need to resolve what method it should call in runtime. It basically knows about that at compile time. The same thing applies to private methods by the way.
Please don’t change everything to a static method 😉
Conclusion
I could hopefully show you how having more smaller and cleaner methods made the code faster in this case. The JVM is rather happy about smaller methods and your fellow co-workers definitely as well. In fact, I have found that the JVM enforces you to think about method sizes and is therefore a perfect bridge between clean coding and performance. They can go hand in hand instead of being mutually exclusive.
Of course, there is more to clean code than just having smaller methods. But personally, I find it to be the most important one next to naming. Smaller methods often allow for more flexible and faster changes to your code. They are also way more readable than big methods and allow your coworkers to better understand your code. One could argue that this is the “performance” you should be looking for. The ability to read and change your code faster and therefore potentially bring value faster to your users is definitely worth it.
And of course, there are also cases where cleaner code is sacrificed for the sake of performance. For example, there is a technique called Loop-unrolling that can make your code faster, but is more or less unclean. As the JVM/JIT compiler can do that for you, you shouldn’t do this on your own when working with Java. For me this is another indicator how good of a companion the JVM is when it comes to clean and performant coding. To be fair, though – it might be very valid for people working with other languages.
The moral of the story: Always profile your code and make the appropriate change if performance is a key-characteristic you’re aiming for. You might get surprised. Don’t sacrifice cleaner code for the purpose of having a probably minor performance benefit. Remember that premature optimization is the root of all evil.
Addendum
The change I did actually made it to the Spring-Framework core in 2016 already and helps our Spring based projects since then as this utility class is used throughout the framework. See the following GitHub PR for more information:
I should also note that both the Spring-Framework and Spring-Boot are probably one of the cleanest projects you will find on GitHub. I’m regularly contributing to them and due to their very well structured code and the awesome maintainers this is a rather pleasant experience. So I hope they don’t mind me taking the above as an example.